Ob Domain-Migration oder Relaunch: Sitzt das Redirect-Mapping nicht, verschwinden bestehende Rankings im Nirvana und Soft 404s treten zu Tage.
Redirect-Mapping ist in der Regel DAS Make-or-Break-Thema im gesamten Relaunch-Projekt ist. Und (bisher) leider auch eines der aufwändigsten. URLs manuell abgleichen, Strukturen vergleichen, Weiterleitungsziele finden – das kostet Zeit, Nerven und ist fehleranfällig. Mit unserem ONE Semantic Mapping ändert sich das. Endlich! Statt rein auf URL-Slugs oder vage Matching-Regeln zu setzen, nutzt du Vektor-Embeddings, um die thematisch und inhaltlich passendsten Zielseiten für jede deiner weiterzuleitenden URLs zu finden. Das Ganze funktioniert auf Basis von Screaming Frog, einem KI-Modell deiner Wahl und einem Colab, das dir das Mapping auf Knopfdruck ausspuckt.
So funktioniert das ONE Semantic Redirect-Mapping
Nachfolgend zeigen wir dir Schritt für Schritt, wie du dein Redirect-Mapping zukünftig automatisiert und dir damit lästige Excel-Augenringe beim Relaunch ersparst. Versprochen.
Let’s dive in 👇
Schritt 1: Tools
Welche Tools und Zugänge brauchst du, um dein Redirect-Mapping mit KI durchführen zu können?
Screaming Frog in der bezahlten Version (hier geht es zum Download)
Einen KI-API-Key für ein Sprachmodell deiner Wahl (z. B. von OpenAI)
Optional: Ein Tool, das dir Backlink-Daten liefert (z. B. ahrefs)
Du brauchst zwei Crawls: einen für die „alte” Domain, die weitergeleitet wird, und einen für die „neue” Domain, auf die weitergeleitet wird.
Wichtig: Ohne einen vollständigen Crawl deiner alten und neuen Domain (inklusive Erzeugung von Vektor-Embeddings) funktioniert das ONE Semantic Redirect-Mapping nicht!
Nachdem du die Domain eingegeben hast (Modus: Spider), geht es im nächsten Schritt an die Crawl-Konfiguration (Konfiguration → Crawl Konfiguration).
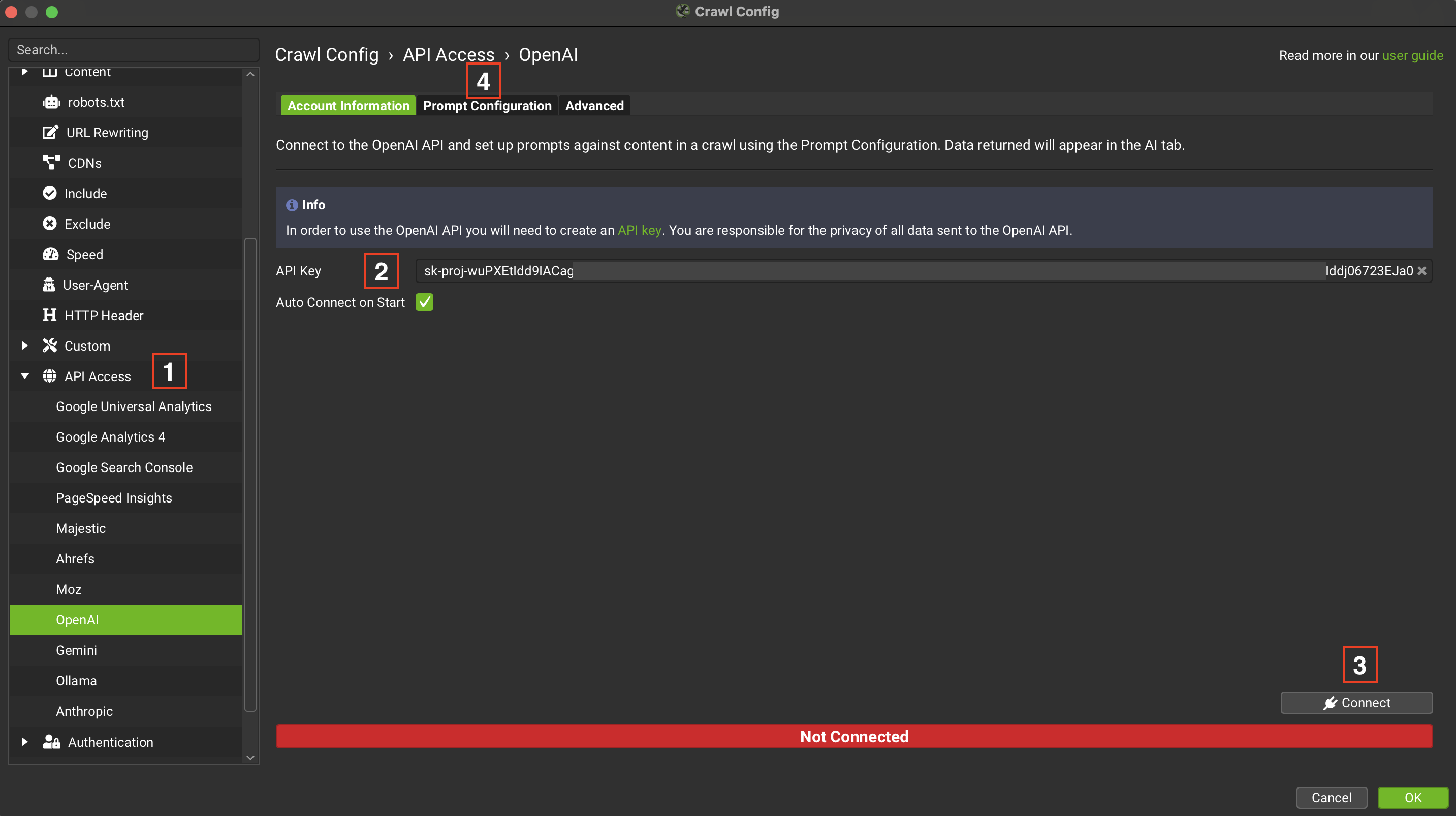
Unter Spider → API-Zugang → die KI auswählen mit der du die Embeddings generieren möchtest – in unserem Fall OpenAI (1). Anschließend trägst du deinen API-Key ein (2) und klickst auf Verbinden (3). Sobald die Verbindung erfolgreich hergestellt ist, geht’s weiter zur Prompt-Konfiguration (4).
Zunächst gilt es sich mit der KI zu koppeln
Hinweis: Die Crawl-Settings sollten in beiden Crawls identisch sein.
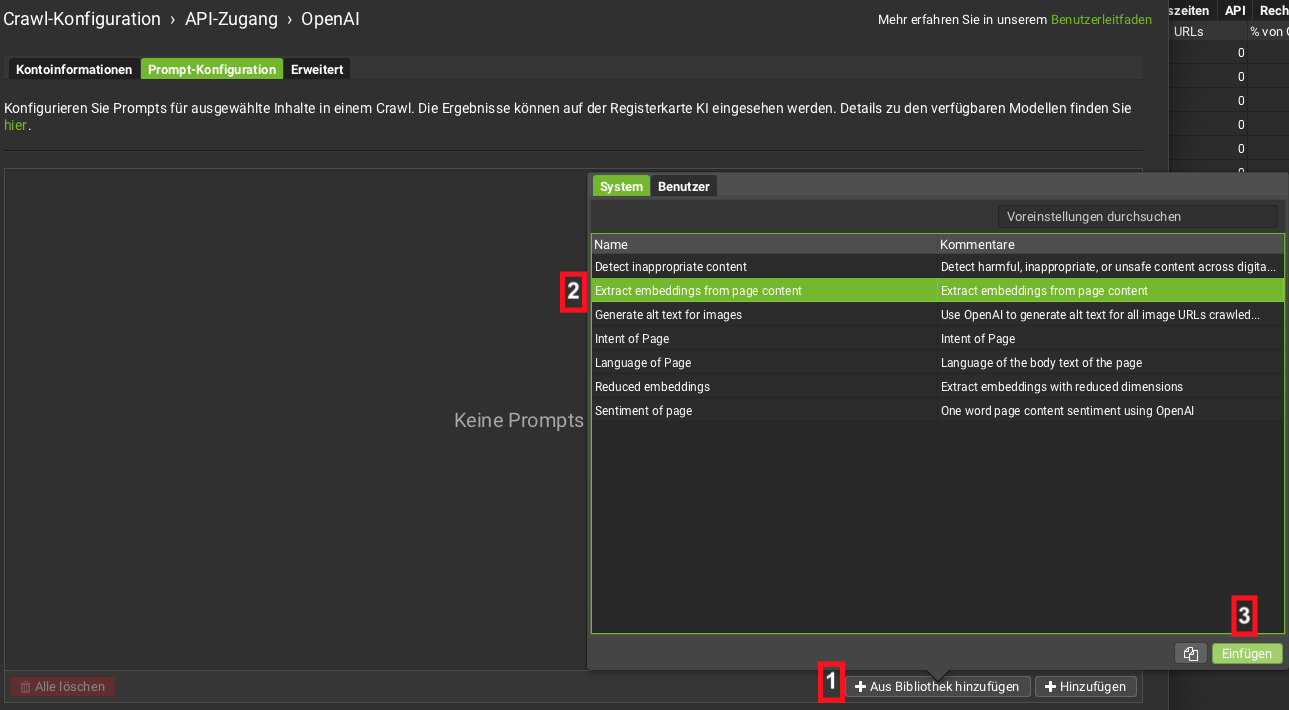
In der Prompt-Konfiguration wählst du über Aus Bibliothek hinzufügen (1) den Eintrag Extract embeddings from page content (2) und fügst ihn anschließend per Klick auf Einfügen (3) ein.
Die Bibliothek des Screaming Frog stellt eine Funktion zur Embedding-Erzeugung bereit
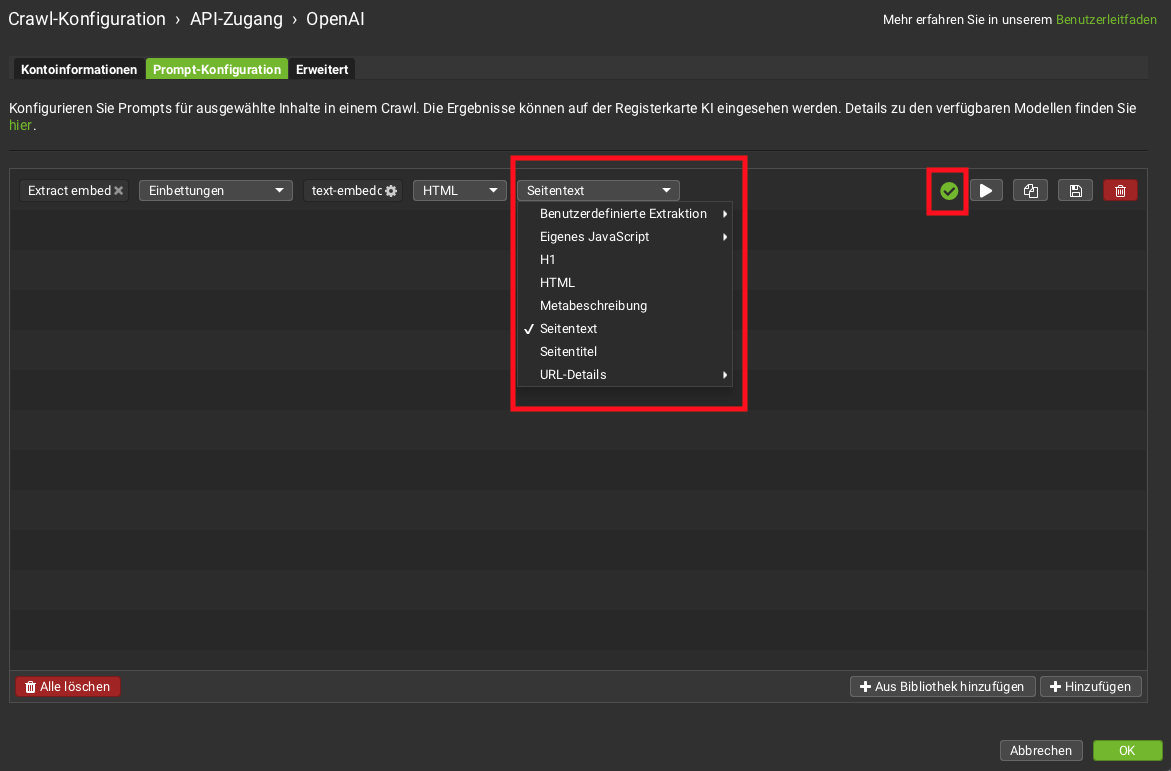
Du solltest dann folgendes sehen:
Embeddings können auf Basis verschiedener (Content-)Elemente erzeugt werden
Sobald das grüne Häkchen erscheint, ist die Prompt-Konfiguration erfolgreich abgeschlossen – der Frog kann Embeddings generieren.
Du kannst das auch vor dem eigentlichen Crawl testen: Klick dazu rechts neben dem Häkchen auf den Play-Button. Es öffnet sich ein neues Fenster mit dem Test-Setup für eine einzelne URL.
Hinweis: Achte darauf, dass die Embeddings auf Basis des vollständigen Seitentexts oder HTML erzeugt werden und nicht nur auf Grundlage der H1 oder einzelner Elemente. Je breiter die inhaltliche Datenbasis, desto präziser wird später das Redirect-Mapping.
Danach bist du „ready to crawl”.
Schritt 3: Crawling und Datenexport
Crawle jetzt die alte und neue Domain.
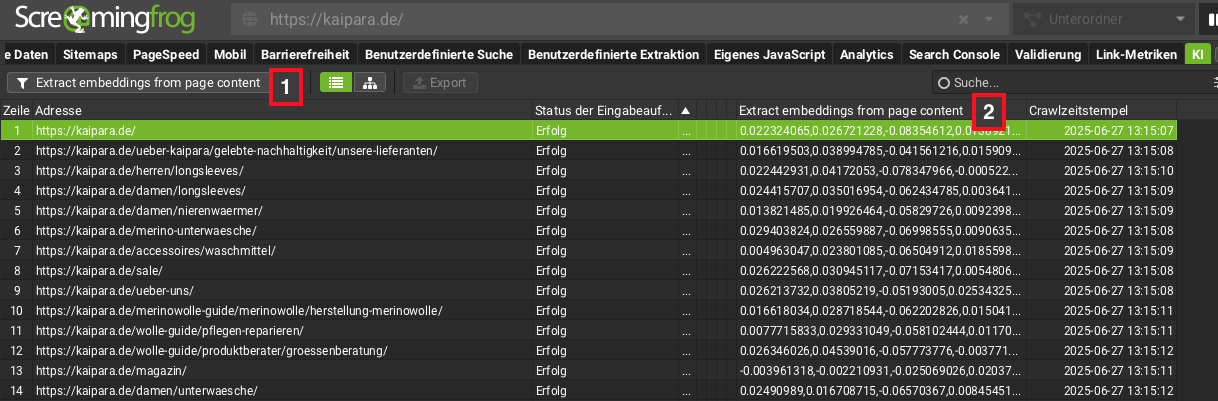
Während der Crawls könnt ihr im Tab KI prüfen, ob die Embeddings korrekt erzeugt werden. Wechselt dazu zu Extract embeddings from page content (1). In der entsprechenden Spalte (2) sollten nun lange Zahlenreihen sichtbar sein. Das ist das Zeichen dafür, dass die Embeddings erfolgreich generiert wurden.
Die Zahlenkolonnen signalisieren: Embedding-Erstellung war erfolgreich
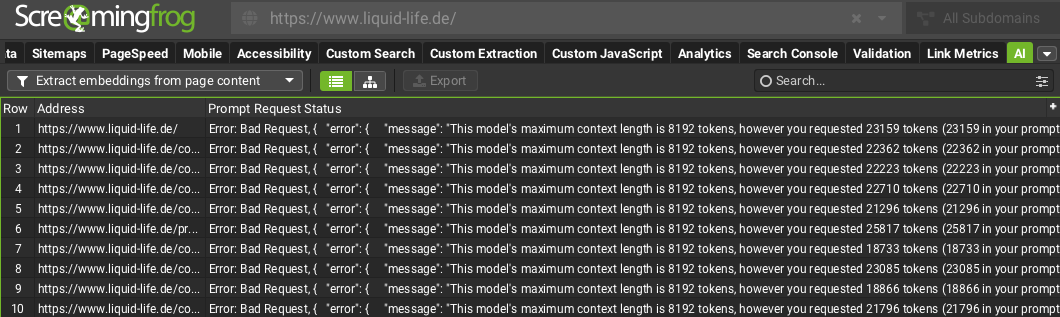
Hilfe! Was mache ich, wenn ich hier Fehlermeldungen ausgespielt bekomme?
Die Fehlermeldung tritt auf, wenn der Seiteninhalt zu umfangreich ist und das von OpenAI erlaubte Eingabelimit / Token-Limit überschreitet. In diesem Fall bricht die API die Verarbeitung mit einem „Bad Request“-Fehler ab und gibt einen Hinweis auf die maximale Token-Anzahl zurück.
Statt Embeddings werden aufgrund der Überschreitung des Token-Limits Fehlermeldungen produziert
Wenn du im KI-Tab keine Zahlen, sondern eine Fehlermeldung siehst, melde dich bei uns. Wir haben die Lösung für dich griffbereit: Mit unserem Custom JavaScript Code wird der Seiteninhalt in kleinere Chunks aufgeteilt und stückweise an OpenAI gesendet. So umgehst du das Token-Limit zuverlässig.
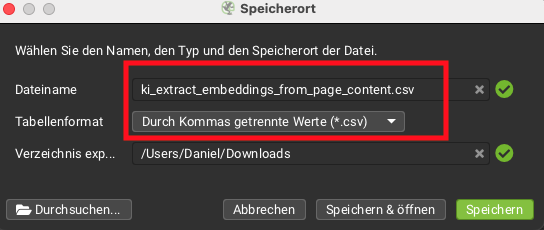
Sobald der Screaming Frog den Crawl abgeschlossen hat, kannst du die Daten exportieren. Wechsle dazu in den Tab KI, klicke auf Export und es erscheint ein Pop-up mit den Speichereinstellungen:
Wichtig: Immer CSV als zu speicherndes Tabellenformat auswählen
Achtung: Screaming Frog vergibt beim Export automatisch einen vorausgewählten Dateinamen. Wenn ihr im Anschluss euren zweiten Crawl exportiert, wird dieser identische Dateiname erneut vorgeschlagen.
Wer hier nicht aufpasst (keine Sorge – Screaming Frog warnt euch nochmal), überschreibt die erste Datei. Wichtig ist auch, dass du als Tabellenformat CSV auswählst.
Sobald du beide Crawl-Dateien heruntergeladen hast, geht’s weiter ins Colab.
Schritt 4: Colab und URL-Mapping
Dort klickst du als Erstes auf den Play-Button, um den Code auszuführen.
Über den Play-Button wird die Ausführung des Codes automatisch angestoßen
Direkt nach dem Start scrollst du bitte ans Ende des Codes und lädtst dort zwei Dateien hoch: die CSV der zu migrierenden Domain (1) und die CSV der Ziel-Domain (2).
Hinweis: Es kann einen Moment dauern, bis die Upload-Maske erscheint. Im Hintergrund muss zunächst das Paket xlsxwriter installiert werden. Das passiert automatisch – du musst hier nichts aktiv anstoßen oder dergleichen.
In der Upload-Maske lädtst du beide Crawl-Dateien hoch
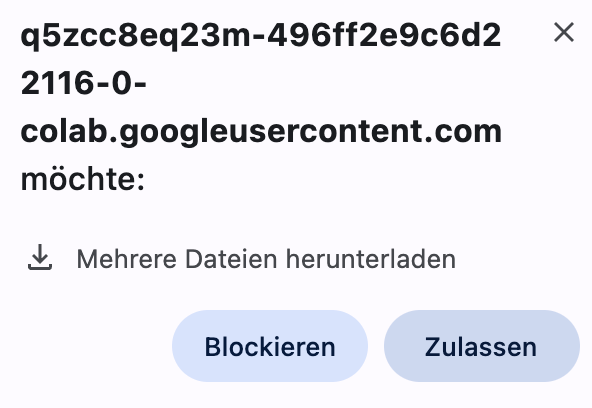
Nach dem erfolgreichen Upload setzt das Colab fort. Sobald die Output-Dateien generiert wurden, wird automatisch der Download angestoßen. Es öffnet sich folgendes Pop-up:
Hier auf Zulassen klicken und die Dateien werden automatisch heruntergeladen
Wenn du dem automatischen Download nicht zustimmst, findest du die fertigen Dateien auch im Content-Ordner in Colab. Hier kannst du den Download manuell durchführen, indem du bei der entsprechenden Datei über das Dreipunkt-Menü gehst (siehst du wenn du über die entsprechende Datei hoverst) und auf Herunterladen klickst.
Jede Input- und Output-Datei ist im Content-Ordner zu finden und kann dort heruntergeladen werden
Hinweis: Es werden immer zwei Output-Dateien generiert – eine Excel („semantic_redirect_mapping.xlsx“) und eine CSV („semantic_redirect_mapping.csv).
Die Excel-Datei ist folgendermaßen aufgebaut
In Spalte A befinden sich die zu migrierenden URLs. In den folgenden Spalten befinden sich, absteigend sortiert nach Ähnlichkeitsscore zur alten URL, die 5 URLs der Ziel-Domain, die sich als Weiterleitungsziel anbieten. Zusätzlich wird zu jeder empfohlenen Zielseite der Ähnlichkeitsscore (Cosine Similarity) und ein Farbscoring für eine bessere Übersichtlichkeit mit ausgegeben.
grün 🟢 = Ähnlichkeitsscore zwischen den URLs ist mind. 0,80
gelb 🟡 = Score liegt zwischen 0,50 und 0,80
rot 🔴 = Ähnlichkeitsscore ist kleiner als 0,50
So ist die Excel aufgebaut
Die URL in der Spalte Best Match URL stellt aus semantischer Sicht das prädestinierte Weiterleitungsziel für die jeweilige alte URL dar.
Ist ein präferiertes Weiterleitungsziel nicht grün eingefärbt, sprich es hat eine Ähnlichkeit von unter 0,80 zur weiterzuleitenden URL, lohnt sich unter Umständen nochmal ein genauerer Blick.
Hinweis: Die CSV wird zusätzlich mit angeboten, da es bei sehr großen Domains vorkommen kann, dass das Excel-Zeichenlimit erreicht wird und so unter Umständen nicht alle Daten mit ausgegeben werden können. Das CSV lässt uns hier deutlich mehr Spielraum. Allerdings musst du bei der CSV beispielsweise auf das Farbscoring verzichten.
Redirect-Mapping war noch nie so einfach
Mit dem ONE Redirect-Mapping Ansatz umschiffst du die größte Stolperfalle bei einem Relaunch: fehlerhafte Weiterleitungen. Schluss mit URL-Slug-Vergleichen und starren Weiterleitungstabellen, unser Ansatz basiert auf echter thematischer Ähnlichkeit. Das sorgt nicht nur für präzisere Weiterleitungen, sondern reduziert auch den manuellen Aufwand erheblich. Unsere Erfahrung zeigt: Rund 80 % der Redirects passen direkt, die restlichen 20 % lassen sich, je nach Domaingröße, gezielt prüfen und feinjustieren. Die menschliche Kontrolle bleibt nach wie vor wichtig, aber der Löwenanteil der Arbeit wird bereits durch KI und das Colab erledigt.
Mit dieser Lösung gibt’s endgültig keinen Grund mehr (gab’s eigentlich noch nie, aber gut), alle URLs stumpf auf die Startseite weiterzuleiten.
Bessere Weiterleitungen, weniger Aufwand – klingt gut? Ist es auch. Überzeuge dich am besten selbst 🙂
Relaunch steht an? Don’t panic. Wir wissen, worauf es ankommt!
Daniel bringt mit seiner Gelassenheit und Ruhe Struktur in die teils überdrehte SEO-Welt – und genau darin liegt seine Stärke. Mit messerscharfem Verstand, werbepsychologisches Feingefühl und einem strategischen Blick für Daten entwickelt er durchdachte und wirkungsvolle SEO-Konzepte. Besonders fasziniert ihn das Potenzial von KI zur Effizienzsteigerung und Skalierung. Als Initiator eines der ersten BVDW-konformen Trainee-Programme gibt er sein Wissen mit Weitblick und Herzblut weiter.
Nehmen Sie unkompliziert mit uns Kontakt auf
Wir freuen uns über Ihre Anfrage! Gerne beraten wir Sie unverbindlich zum passenden SEO-Thema. Oder schreiben Sie uns direkt eine Email an: hello@onebeyondsearch.com
Vielen Dank.
Wir haben Ihre Anfrage erhalten und melden uns umgehend bei Ihnen.